图解Janusgraph系列-并发安全:Lock锁机制(本地锁+分布式锁)分析
在分布式系统中,难免涉及到对同一数据的并发操作,如何保证分布式系统中数据的并发安全呢?分布式锁!
大家好,我是洋仔,JanusGraph图解系列文章,实时更新~
图数据库文章总目录:
- 整理所有图相关文章,请移步(超链):图数据库系列-文章总目录
- 地址:https://liyangyang.blog.csdn.net/article/details/111031257
**
源码分析相关可查看github(码文不易,求个star~)**: https://github.com/YYDreamer/janusgraph
下述流程高清大图地址:https://www.processon.com/view/link/5f471b2e7d9c086b9903b629
版本:JanusGraph-0.5.2
转载文章请保留以下声明:
作者:洋仔聊编程
微信公众号:匠心Java
原文地址:https://liyangyang.blog.csdn.net/
在分布式系统中,难免涉及到对同一数据的并发操作,如何保证分布式系统中数据的并发安全呢?分布式锁!
一:分布式锁
常用的分布式锁实现方式有三种:
1、基于数据库实现分布式锁
针对于数据库实现的分布式锁,如mysql使用使用for update共同竞争一个行锁来实现; 在JanusGraph中,也是基于数据库实现的分布式锁,这里的数据库指的是我们当前使用的第三方backend storage,具体的实现方式也和mysql有所不同,具体我们会在下文分析
2、基于Redis实现的分布式锁
基于lua脚本+setNx实现
3、基于zk实现的分布式锁
基于znode的有序性和临时节点+zk的watcher机制实现
4、MVCC多版本并发控制乐观锁实现
本文主要介绍Janusgraph的锁机制,其他的实现机制就不在此做详解了
下面我们来分析一下JanusGraph的锁机制实现~
二:JanusGraph锁机制
在JanusGraph中使用的锁机制是:本地锁 + 分布式锁来实现的;
2.1 一致性行为
在JanusGraph中主要有三种一致性修饰词(Consistency Modifier)来表示3种不同的一致性行为,来控制图库使用过程中的并发问题的控制程度;
1 | public enum ConsistencyModifier { |
源码中ConsistencyModifier枚举类主要作用:用于控制JanusGraph在最终一致或其他非事务性后端系统上的一致性行为!其作用分别为:
- DEFAULT:默认的一致性行为,不使用分布式锁进行控制,对配置的存储后端使用由封闭事务保证的默认一致性模型,一致性行为主要取决于存储后端的配置以及封闭事务的(可选)配置;无需显示配置即可使用
- LOCK:在存储后端支持锁的前提下,显示的获取分布式锁以保证一致性!确切的一致性保证取决于所配置的锁实现;需
management.setConsistency(element, ConsistencyModifier.LOCK);语句进行配置 - FORK:只适用于
multi-edges和list-properties两种情况下使用;使JanusGraph修改数据时,采用先删除后添加新的边/属性的方式,而不是覆盖现有的边/属性,从而避免潜在的并发写入冲突;需management.setConsistency(element, ConsistencyModifier.FORK);进行配置
LOCK
在查询或者插入数据时,是否使用分布式锁进行并发控制,在图shcema的创建过程中,如上述可以通过配置schema元素为ConsistencyModifier.LOCK方式控制并发,则在使用过程中就会用分布式锁进行并发控制;
为了提高效率,JanusGraph默认不使用锁定。 因此,用户必须为定义一致性约束的每个架构元素决定是否使用锁定。
使用JanusGraphManagement.setConsistency(element,ConsistencyModifier.LOCK)显式启用对架构元素的锁定
代码如下所示:
1 | mgmt = graph.openManagement() |
FORK
由于边缘作为单个记录存储在基础存储后端中,因此同时修改单个边缘将导致冲突。
FORK就是为了代替LOCK,可以将边缘标签配置为使用ConsistencyModifier.FORK。
下面的示例创建一个新的edge label,并将其设置为ConsistencyModifier.FORK
1 | mgmt = graph.openManagement() |
经过上述配置后,修改标签配置为FORK的edge时,操作步骤为:
- 首先,删除该边
- 将修改后的边作为新边添加
因此,如果两个并发事务修改了同一边缘,则提交时将存在边缘的两个修改后的副本,可以在查询遍历期间根据需要解决这些副本。
注意edge fork仅适用于MULTI edge。 具有多重性约束的边缘标签不能使用此策略,因为非MULTI的边缘标签定义中内置了一个唯一性约束,该约束需要显式锁定或使用基础存储后端的冲突解决机制
下面我们具体来看一下janusgrph的锁机制的实现:
2.2 LoackID
在介绍锁机制之前,先看一下锁应该锁什么东西呢?
我们都知道在janusgraph的底层存储中,vertexId作为Rowkey,属性和边存储在cell中,由column+value组成
当我们修改节点的属性和边+边的属性时,很明显只要锁住对应的Rowkey + Column即可;
在Janusgraph中,这个锁的标识的基础部分就是LockID:
LockID = RowKey + Column
源码如下:
1 | KeyColumn lockID = new KeyColumn(key, column); |
2.3 本地锁
本地锁是在任何情况下都需要获取的一个锁,只有获取成功后,才会进行下述分布式锁的获取!
本地锁是基于图实例维度存在的;主要作用是保证当前图实例下的操作中无冲突!
本地锁的实现是通过ConcurrentHashMap数据结构来实现的,在图实例维度下唯一;
基于当前事务+lockId来作为锁标识;
获取的主要流程:
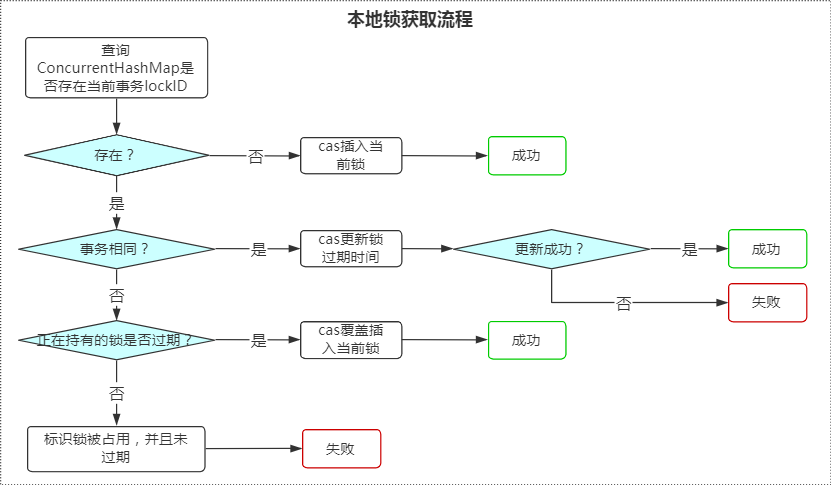
结合源码如下:
上述图建议依照源码一块分析,源码在LocalLockMediator类中的下述方法,下面源码分析模块会详细分析
1 | public boolean lock(KeyColumn kc, T requester, Instant expires) { |
引入本地锁机制,主要目的: 在图实例维度来做一层锁判断,减少分布式锁的并发冲突,减少分布式锁带来的性能消耗
2.4 分布式锁
在本地锁获取成功之后才会去尝试获取分布式锁;
分布式锁的获取整体分为两部分流程:
分布式锁信息插入分布式锁信息状态判断
分布式锁信息插入
该部分主要是通过lockID来构造要插入的Rowkey和column并将数据插入到hbase中;插入成功即表示这部分处理成功!
具体流程如下:
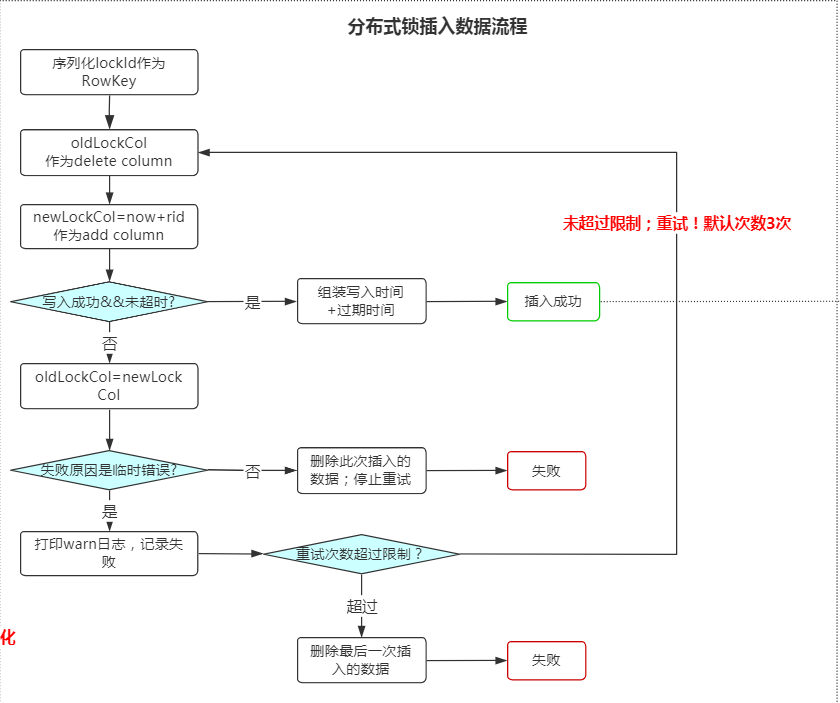
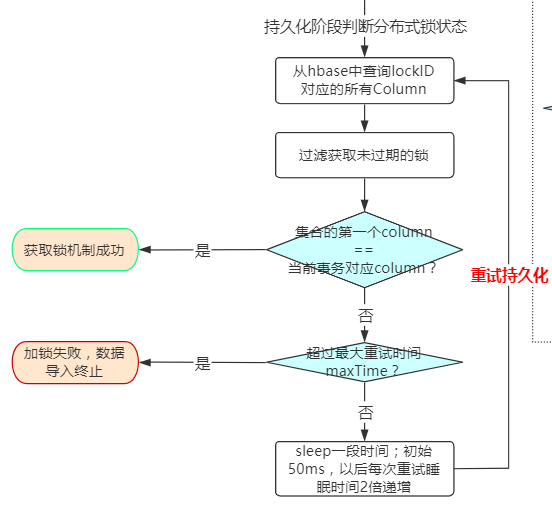
分布式锁信息状态判断
该部分在上一部分完成之后才会进行,主要是判断分布式锁是否获取成功!
查询出当前hbase中对应Rowkey的所有column,过滤未过期的column集合,比对集合的第一个column是否等于当前事务插入的column;
等于则获取成功!不等于则获取失败!
具体流程如下:
三:源码分析 与 整体流程
源码分析已经push到github:https://github.com/YYDreamer/janusgraph
1、获取锁的入口
1 | public void acquireLock(StaticBuffer key, StaticBuffer column, StaticBuffer expectedValue, StoreTransaction txh) throws BackendException { |
2、执行 locker.writeLock(lockID, tx.getConsistentTx()) 触发锁获取
1 | public void writeLock(KeyColumn lockID, StoreTransaction tx) throws TemporaryLockingException, PermanentLockingException { |
包含两个部分:
- 本地锁的获取
lockLocally(lockID, tx) - 分布式锁的获取
writeSingleLock(lockID, tx)注意此处只是将锁信息写入到Hbase中,并不代表获取分布式锁成功,只是做了上述介绍的第一个阶段分布式锁信息插入
3、本地锁获取 lockLocally(lockID, tx)
1 | public boolean lock(KeyColumn kc, T requester, Instant expires) { |
如上述介绍,本地锁的实现是通过ConcurrentHashMap数据结构来实现的,在图实例维度下唯一!
4、分布式锁获取第一个阶段:分布式锁信息插入
1 | protected ConsistentKeyLockStatus writeSingleLock(KeyColumn lockID, StoreTransaction txh) throws Throwable { |
上述只是将锁信息插入,插入成功标识该流程结束
5、分布式锁获取第一个阶段:分布式锁锁定是否成功判定
这一步,是在commit阶段进行的验证
1 | public void commit() throws BackendException { |
最终会调用checkSingleLock方法,判断获取锁的状态!
1 | protected void checkSingleLock(final KeyColumn kc, final ConsistentKeyLockStatus ls, |
四:整体流程
总流程如下图:
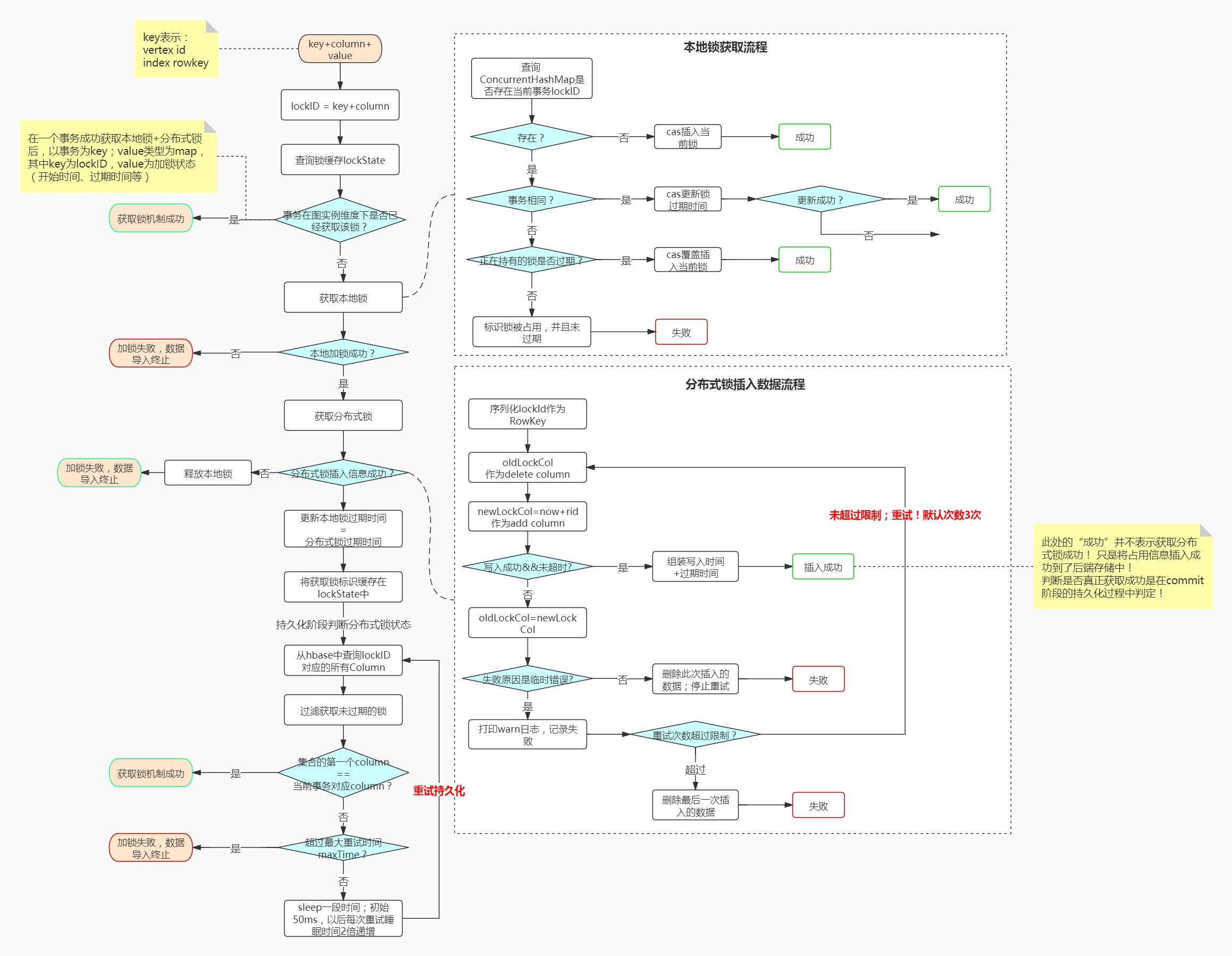
整体流程为:
- 获取本地锁
- 获取分布式锁
- 插入分布式锁信息
- commit阶段判断分布式锁获取是否成功
- 获取失败,则重试
五:总结
JanusGraph的锁机制主要是通过本地锁+分布式锁来实现分布式系统下的数据一致性;
分布式锁的控制维度为:property、vertex、edge、index都可以;
JanusGraph支持在数据导入时通过前面一致性行为部分所说的LOCK来开关分布式锁:
- LOCK:数据导入时开启分布式锁保证分布式一致性
- DEFAULT、FORK:数据导入时关闭分布式锁
是否开启分布式锁思考:
在开启分布式锁的情况下,数据导入开销非常大;如果是数据不是要求很高的一致性,并且数据量比较大,我们可以选择关闭分布式锁相关,来提高导入速度;
然后,针对于小数据量的要求高一致性的数据,单独开启分布式锁来保证数据安全;
另外,我们在不开启分布式锁定的情况下,可以通过针对于导入的数据的充分探查来减少冲突!
针对于图schema的元素开启还是关闭分布式锁,还是根据实际业务情况来决定。
本文有任何问题,可加博主微信或评论指出,感谢!
码文不易,给个赞和star吧~
图解Janusgraph系列-并发安全:Lock锁机制(本地锁+分布式锁)分析
http://coderstudy.vip/article/图解Janusgraph系列-并发安全:Lock锁机制(本地锁+分布式锁)分析.html
